Tự động, công ty đằng sau nó WordPress và Tumblr, đang đàm phán để kiếm tiền từ nội dung của người dùng bằng cách bán dữ liệu của mình cho các công ty AI, bao gồm MidJourney và OpenAI. Dữ liệu này từ nền tảng blog Tumblr và WordPress.com sẽ được sử dụng để đào tạo modecủa AI.
Mặc dù chi tiết về giao dịch vẫn chưa rõ ràng, nhưng tin tức này đã làm dấy lên mối lo ngại của người dùng về việc nội dung riêng tư của họ có thể bị lạm dụng trên hai nền tảng blog. 404 Media cũng gợi ý rằng xung đột nội bộ đã nảy sinh trong Automattic vì nội dung được thu thập bao gồm dữ liệu riêng tư không nhằm mục đích lưu giữ trong công ty.
Để đối phó với phản ứng dữ dội, Automattic chuẩn bị giới thiệu một tính năng mới cho phép người dùng từ chối chia sẻ dữ liệu của họ để đào tạo AI. Công ty, trong một bài đăng trên blog, khẳng định cam kết cung cấp cho người dùng Tumblr và WordPress kiểm soát tốt hơn nội dung của họ. Nó đề cập đến việc ra mắt cài đặt nhằm "không khuyến khích các công ty AI khám phá", giải thích rằng các nền tảng khám phá AI hàng đầu bị chặn theo mặc định.
Vấn đề sử dụng nội dung từ blog của các công ty phát triển modele AI, không chỉ giới hạn ở các nền tảng do công ty Automattic quản lý. rất nhiều OpenAI giống như Google, sử dụng c-botrawler qua đó tôi thu thập thông tin từ tất cả các trang web, để đào tạo modelele trí tuệ nhân tạo. Quá trình này tương tự như việc thu thập dữ liệu của các công cụ tìm kiếm.
Làm thế nào bạn có thể chặn OpenAI và Gemini (Bard) lấy dữ liệu từ blog của bạn?
Nếu bạn là chủ sở hữu của một blog hoặc trang web và không muốn sử dụng dữ liệu từ đó cho mục đích đào tạo modecủa trí tuệ nhân tạo OpenAI và Gemini, bạn có thể chặn bot (crawlers) vào nội dung. Hạn chế này có thể được đặt thông qua tệp robots.txt.
OpenAI Crawlers
User-agent: GPTBot
Disallow: /Gemini Crawlers
User-agent: Google-Extended
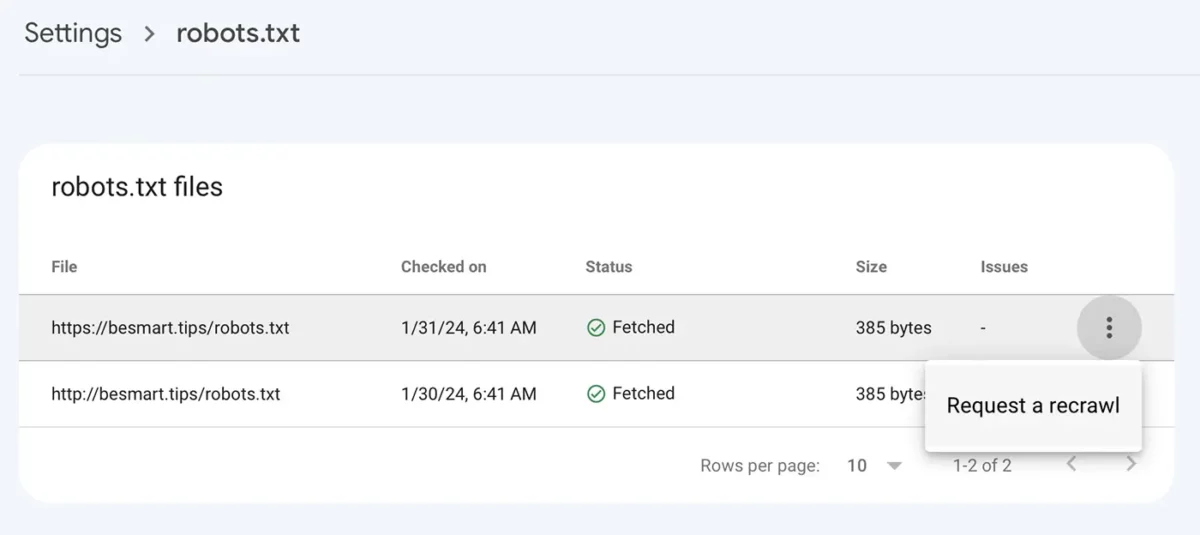
Disallow: /Sau khi bạn lưu tệp robots.txt với các dòng mới, hãy truy cập Google Console để: Settings > robots.txt > nhấp vào menu có ba dấu chấm, nhấp vào "Request a recrawl".
Liên quan: GPT-5 và con trình duyệt web mới GPTBot do OpenAI phát triển.
Đối với người dùng Tumblr và WordPress, quyền truy cập truy xuất dữ liệu từ blog bởi OpenAI hoặc các công ty phát triển trí tuệ nhân tạo khác, sẽ có thể bị chặn bằng các công cụ do công ty Automattic cung cấp.