Hầu hết thời gian, khi bạn cần chặn truy cập SeekportBot hoặc những người khác crawl bots với một trang web, lý do rất đơn giản. Nhện web thực hiện quá nhiều lượt truy cập trong một khoảng thời gian ngắn và yêu cầu tài nguyên của máy chủ web hoặc nó đến từ một công cụ tìm kiếm mà bạn không muốn trang web của mình được lập chỉ mục.
Nó rất có lợi cho một trang web được truy cập bởi crawTôi va vào anh ta. Những trình thu thập dữ liệu web này được thiết kế để khám phá, xử lý và lập chỉ mục nội dung của các trang web trong công cụ tìm kiếm. Google và Bing sử dụng crawTôi va vào anh ta. Tuy nhiên, cũng có những công cụ tìm kiếm sử dụng robot để thu thập dữ liệu từ các trang web. Seekport là một trong những công cụ tìm kiếm này, sử dụng crawcông cụ SeekportBot để lập chỉ mục các trang web. Thật không may, đôi khi nó sử dụng nó quá mức và tạo ra lưu lượng không cần thiết.
Nội dung
SeekportBot là gì?
SeekportBot là một web crawler được phát triển bởi công ty Seekport, có trụ sở tại Đức (nhưng sử dụng IP từ một số quốc gia, bao gồm cả Phần Lan). Bot này được sử dụng để thu thập dữ liệu và lập chỉ mục các trang web để chúng có thể được hiển thị trong kết quả của công cụ tìm kiếm. Seekport. Một công cụ tìm kiếm phi chức năng, theo như tôi có thể nói. Ít nhất, nó không trả lại bất kỳ kết quả nào cho tôi cho bất kỳ cụm từ khóa nào.
SeekportBot Sử dụng user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"Cách chặn quyền truy cập vào SeekportBot hoặc crawTôi đã nhấp vào một trang web
Nếu bạn đã đi đến kết luận rằng không cần thiết phải quét toàn bộ trang web của mình và tạo lưu lượng truy cập không cần thiết đến máy chủ web, thì bạn có một số phương pháp để có thể chặn quyền truy cập của chúng.
Tường lửa ở cấp máy chủ web
Chúng là các ứng dụng tường lửa open-source có thể được cài đặt trên hệ điều hành Linux và có thể được cấu hình để chặn lưu lượng dựa trên một số tiêu chí. Địa chỉ IP, vị trí, cổng, giao thức hoặc tác nhân người dùng.
APF (Advanced Policy Firewall) là một phần mềm mà qua đó bạn có thể chặn các bot không mong muốn, ở cấp độ máy chủ.
Vì SeekportBot và các trình thu thập dữ liệu web khác sử dụng nhiều khối IP nên quy tắc chặn hiệu quả nhất dựa trên "user agent“. Vì vậy, nếu bạn muốn chặn truy cập SeekportBot bằng APF, tất cả những gì bạn phải làm là kết nối với máy chủ web qua SSHvà thêm quy tắc bộ lọc vào tệp cấu hình.
1. Mở tệp cấu hình bằng nano (hoặc nhà xuất bản khác).
sudo nano /etc/apf/conf.apf2. Tìm dòng bắt đầu bằng “IG_TCP_CPORTS” và thêm tác nhân người dùng mà bạn muốn chặn ở cuối dòng này, theo sau là dấu phẩy. Ví dụ, nếu bạn muốn chặn user agent "SeekportBot", dòng sẽ trông như thế này:
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. Lưu tệp và khởi động lại dịch vụ APF.
sudo systemctl restart apf.serviceQuyền truy cập "SeekportBot" sẽ bị chặn.
Bộ lọc web crawls với sự trợ giúp của Cloudflare – Chặn quyền truy cập của SeekportBot
Với sự trợ giúp của Cloudflare, đối với tôi, đây dường như là phương pháp an toàn và thuận tiện nhất mà bạn có thể hạn chế quyền truy cập của một số bot vào một trang web theo nhiều cách khác nhau. Phương pháp tôi cũng đã sử dụng trong trường hợp SeekportBot để lọc lưu lượng truy cập vào một cửa hàng trực tuyến.
Giả sử rằng bạn đã thêm trang web vào Cloudflare và các dịch vụ DNS được kích hoạt (nghĩa là lưu lượng truy cập vào trang web đi qua Cloudflare), hãy làm theo các bước bên dưới:
1. Mở tài khoản Clouflare của bạn và truy cập trang web mà bạn muốn giới hạn quyền truy cập.
2. Truy cập: Security → WAF và thêm một quy tắc mới. Create rule.
3. Chọn tên cho quy tắc mới, Field: User Agent – Operator: Contains – Value: SeekportBot (hoặc tên bot khác) – Choose action: Block – Deploy.
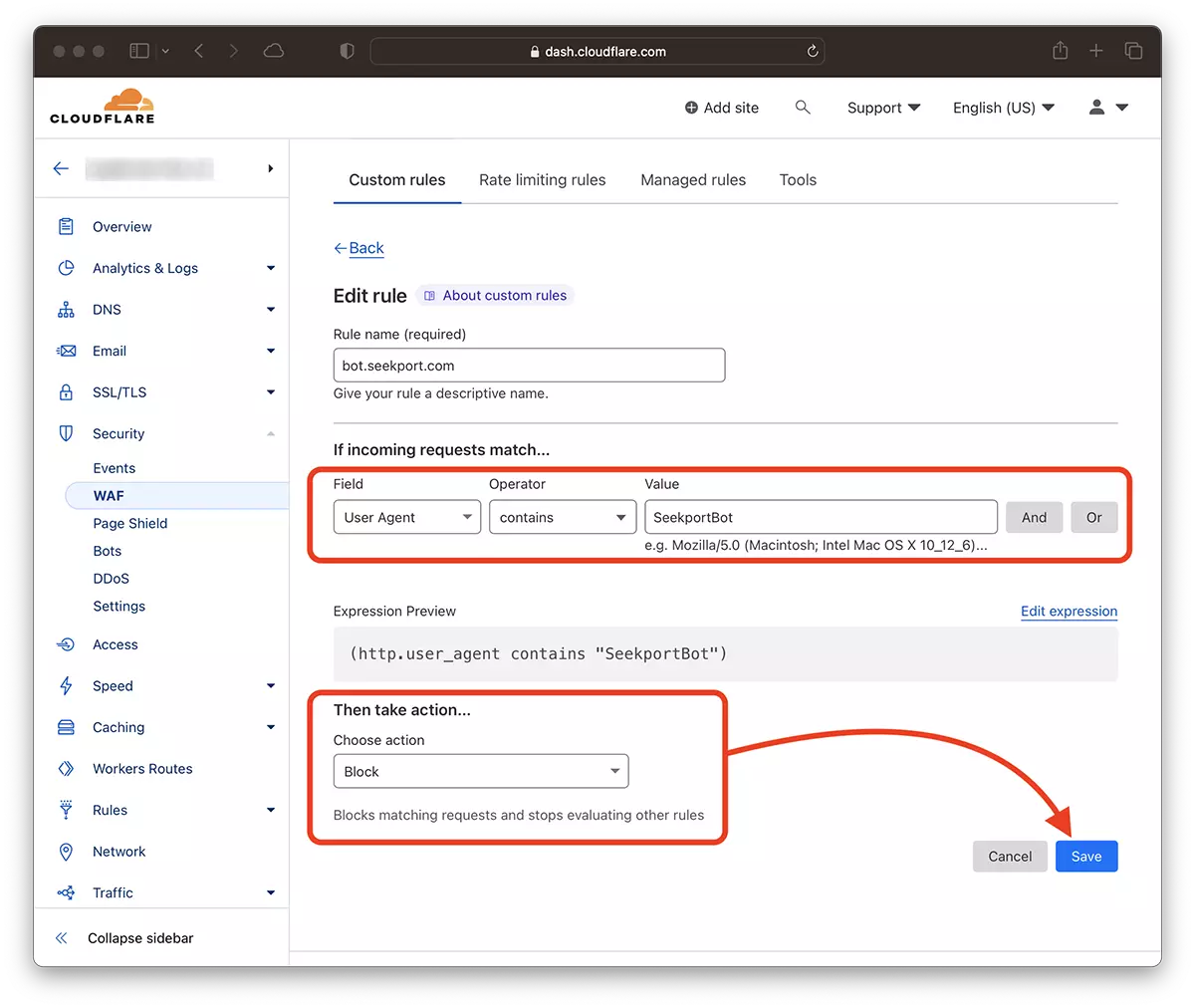
Chỉ trong vài giây, quy tắc mới WAF (Web Application Firewall) nó bắt đầu có hiệu lực.
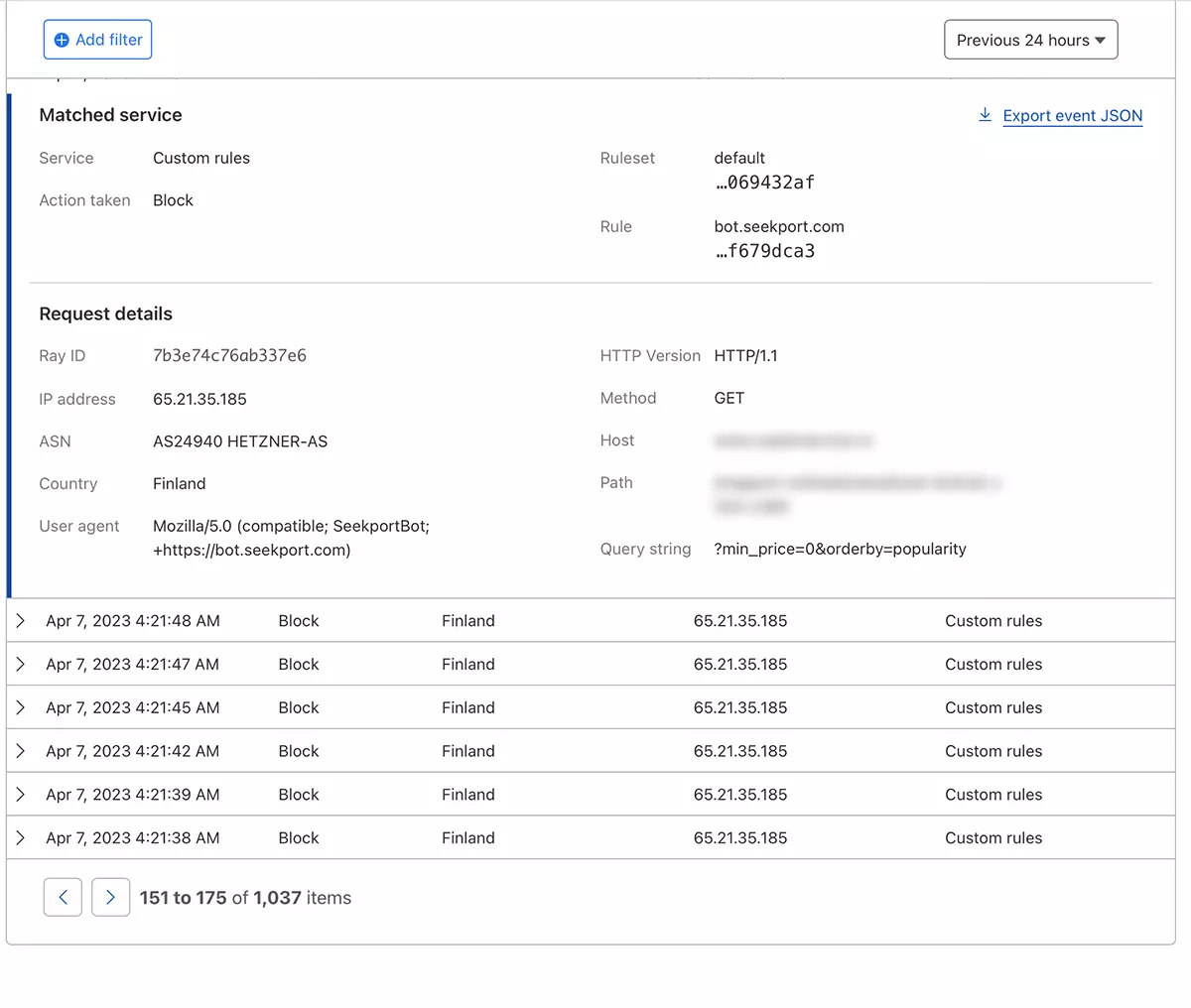
Về lý thuyết, tần suất mà một con nhện web truy cập vào một trang web có thể được đặt từ robots.txt, nhưng ... đó chỉ là trên lý thuyết.
User-agent: SeekportBot
Crawl-delay: 4Nhiều web crawlerii (ngoại trừ Bing và Google) không tuân theo các quy tắc này.
Tóm lại, nếu bạn xác định được một web crawl ai truy cập quá nhiều vào trang web của bạn, tốt nhất là chặn hoàn toàn quyền truy cập của anh ta. Tất nhiên, nếu bot này không phải từ một công cụ tìm kiếm mà bạn muốn có mặt.